
🖖🏻 It's Data Jim, but not as we know it 🖖🏻
The long tail problem of moving to a data driven and data centric view of the world/ network.

Disclaimer
I’m a network engineer by trade and not a developer, DevOPS, platform engineer and/ or a data engineer/ DBA, therefore the thoughts below are moving towards a vision/ utopian state, rather than best practices.
The Value Proposition
One of the biggest hurdles within an organisation when on a “data transformation” journey is the cost of storing the data. Whether the data is a rest, hot, warm, lukewarm, cold or freezing/ frozen, it’s a KB here and a KB there of data which soon adds up.
However in a data driven world data is king/ queen/ $insert deity of choice$. Without it a modern network operator is blind to what is happening in their network, and so there’s unexplainable outages, missed opportunities for proactive intervention, and overall a poor customer experience.
So how do you turn that data into something valuable? Well unlike social networks or cookie scrapers for telecommunications providers, I see the following top three as the drivers/ KPIs for any business case:
Customer Experience/ Satisfaction
A happy customer in telco is a quiet customer. And other than consuming connectivity, therefore a fractal of last mile equipment, an even smaller fractal of a local point-of-presence (PoP), a minute fractal of subscriber termination, backhaul, peering and transit; the total cost of keeping the customer is relatively low.
The upside of this, is depending on how “active” in any community they are, there’s free PR; “Hey $TELCO$ is great, the service just works and …”, and (as long as there’s no shocking price hikes (Q4 2025 O2 Price Hike), they’ll stay a subscriber of the service until either performance/ experience drops or the value (typically price point) of another service becomes more attractive.
Mean Time to Innocence (MTTI) or not
“The $NETWORK$ is down” … “It’s always the $NETWORKS$ fault”
The one thing I’ve learnt in my years of experience operating networks, the faster you can prove the innocence or not, of a network, the faster the problem is resolved.
And with modern networks getting less complicated technologically, but more ‘noisy’ data wise in regards the number of customers using the network, that means traditional ways of monitoring the network and the logging of the data have become obsolete.
And the data that drives the MTTI, is one of the linchpins of keeping customer experience/ satisfaction high for using your network.
Cost to Serve
The ‘elephant in the room’ if you will, is the ‘ugly’ topic of the costs. There's the costs to get a connection to a customer, then the costs of ‘acquiring’ the customer (yes for those who don’t deal with the commercial/ product side of a business, that is a term), the costs of maintaining the customer, and finally the costs of disconnecting the customer; the customer lifecycle.
Connecting and Acquisition
Whilst data has limited impact on connecting and acquiring the customer, other than the best and most economical route to get to said customer and what package would best suit and be attractive to sad customer, the major drivers for those costs are time and resources.
So the better the data is about what is needed to connect a customer and the time needed to achieve a good quality job, or about what demographics are in the area to offer targets deals either based on their preferences or time of year, i.e., “Hey $INSERT_NAME$, you’ve had multiple WiFi faults this year, would you like to upgrade to the ‘whole home' WiFi’ package a Z% discount rate?” or “As $INSERT_GAME$ is sending out $UPDATE_SIZE$ patch on the $INSERT_DATE$ would you like a speed boost to $INSERT_TOP_PACKAGE$ for 12hrs to make sure you can get the game as fast as possible?”
Maintaining the Customer
As described above in Mean Time to Innocence (MTTI) or not, the data is king/ queen/ $insert deity of choice$.
So imagine (if you will) gaining the ability to be proactive and turn the contact centre into a revenue generating position of a business, rather than a cost overhead.
What do I mean by this? Well turning the ‘flow’ (if you will) of how a contact centre engages with the customer base from “Hello, my name is X, how can I help you today?”, to “Hello, my name is A from BCORP and we suspect that there might be a fault due to occur on your service/ in your area, would it be ok for BCORP to book an appointment with you so that C can visit you to do proactive work?”.
Alternatively in a reactive situation, messaging the customer BEFORE they try and call in 😱🤯 “Hello, this is BCORP we have notice a problem with your service, please see $URL$ for live updates. We will message you again in X minutes/ hours (depending on SLA) with an update”. And in said updates, being able to have clear and concise, data centric updates from the data driven insights (not marketing fluff).
Now that might not be the exact method or style of engagement (I’m no marketeer or public relations guru, I’m more of a ‘networks guy’), however the ‘power’ of getting ahead of something builds confidence and trust in the customer base.
That’s All Very Nice, However How Can This Be Done?
So with the skeleton of WHY above, and some of the WHAT covered in my previous post 🤖 “I have detailed files” 🤖, the HOW starts to form based on 🎶 Do you want to find a Network? 🎶.
What Does The Ecosystem Look Like?
Strangely enough we’re going to start embarking on a fairly familiar journey, automation. The difference is, this is focused on WHAT can be done and some direction/ options on HOW to do it (not every option fits every organisation), rather than dry prescriptive ‘play nicely with each other’ “standards”, and finally a utopian endgame which I hope we can see in my lifetime, autonomics.
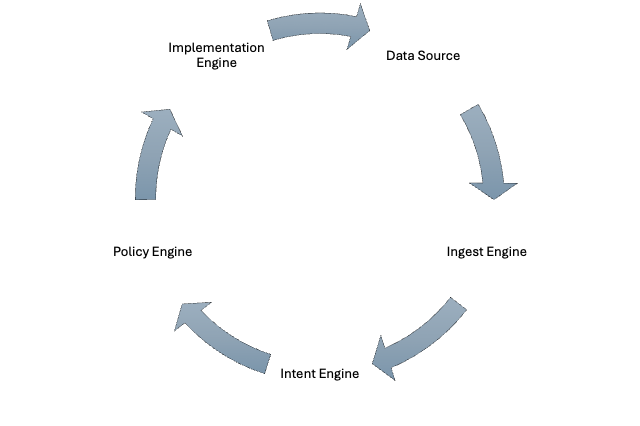
Drinking From The Firehose
So as stated previously, modern networks are generating more and more data “noise” and this is due to increasing customers taking the service, and observability required to maintain the service (or a developer leaving the debugging turned on and pushing to the live/ deployed code base 🤦🏻).
Now the ‘knee jerk’ option is to start filtering, however I recommend collecting all of the data and keeping it as long as needed whilst observing the legal boundaries that you have to operate your network(s) in.
Doing this brings it’s own challenges, fundamentally the legal requirements and cost, hence me starting this post with the WHY statement.
Where Will the Data Come From? “Data Source”
Data is generated within a system, closed or open.
For networking the common ways to communicate the telemetry data (streaming telemetry/ dial-out) is via; RADIUS, Syslog, SNMP traps, gNMI, NETCONF, IPFix and several others (including vendor proprietary). There are also dial-in options such as SNMP, gNMI and NETCONF. Typically these pieces of data are stored in a database or a log file with limited or no API. Therefore, an API is needed.
For systems/ software these tend to be dial-out options, whereby the ‘north’ system makes a ‘southbound’ request to the supplicant system via an API, i.e., an Operations Support Systems (OSS) stack will make a provisioning request via API to the Network Management System (NMS) or Element Management System (EMS). Typically this is a API platform with a WebUI, (until the humans are no longer needed).
The foundational block of this, is to build data products and build them per role type, and the ingest data products should be laid out the same way that the Implementation/ Intent Engine products are, to help maintain the Imperatives (inside the Policy Engine), however more about that later.
Overall as there are several sources of disparate data, so building relationships between them is critical to the longterm success, especially as the entropy of the data grows.
How to Collect the Data? “Ingest Engine”
As there’s so many sources of data, and in an operational network a lot of outcomes from the data are only needed in and around the area that it was generated, then using local caches/ agents (see Autonomic Service Agents (ASAs)) is a way forward.
This also means that local processing is required and anything:
outside of the:
compute capabilities.
current interaction sets/ training models.
which is needed globally (i.e., RADIUS, event alarms).
Should then be processed at a central location, before being returned to the local store to be actioned in the subsequent engines.
Once processed events can be sent back to a central location for wider viewing and understanding.
How to Store the Data? “Ingest Engine”
Now this is where the nuances start.
So, an example of this is say, an Optical Line Termination (OLT) device. An OLT will generate data for the:
User Network Interface (UNI) port on an Optical Network Terminal (ONT) unit
Throughout
Speed of the interface
Duplex of the interface
CRC errors
… etc.
The light levels of the PON port of the ONT
The light levels of the PON port of the OLT
… etc. (see 🤖 “I have detailed files” 🤖, for more info)
For the most part it will generate that information in a standards based way, although the units of the output might vary, i.e., interface speeds are now in the Gbps, however for some vendors when the code for the Network Operating System (NOS) was created the speeds were in the Kbps or Mbps, so the units needs refactoring.
However when it comes to the logging of its events bus, that’s when things go proprietary, and normalisation in my opinion is the best way to deal with this at scale. Otherwise you’re such with a large matrix of event triggers which can become cumbersome. Whereas normalisation can follow an If This, Then That (ITTT) approach, which is more logical for a human to backtrace.
Finally you need to ‘join the dots’. Ultimately there should be a data product per element with a view using the profile applied based on its role in the network. However as services are provisioned over said network element, the service will need a relationship creating with the element(s), based on the resource(s) it consumes from said element(s). There’s a few ‘schools of though’ on this, and whilst as I said above I’m not a DBA, I personally visualise this as a 3D graph/ model, using nodes to set the anchor(s) and the values are then associated with the nodes. This is so a value can change (such as an IP address, VLAN ID, interface number … etc.), and not break the relationship; unless the node needs to be removed/ deleted, i.e., the line card is removed.
Example graph relationships

Normalising with Data Privacy
Whilst this is easier said than done, I believe that aiming for a normalised view of (or at least a way to view) the data with data privacy at the heart will break the back of this problem. The reality, is vendors of hardware and software have little or no incentive to do this, never mind the quagmire of trying to inflict this via a standards body.
Ok, so how can this be achieved? One option is to use Large Language Models (LLMs) and train it on key word analysis on a per vendor per solution in order to gain insights and analysis. If this is done in conjunction with a Data Mesh architecture, it means the next step of joined up thinking (finding the signal in the noise), can begin.
Replication and Redundancy
So the likes of the hyperscalers and content distribution networks have grappled with this for some time and the likes of Netflix have published several articles which are worth looking into. I don’t fully understand the HOW parts of these articles, however the WHAT is simple; data needs to be replicated, as disparate systems need access to the same information, however said data needs to be clean, uncorrupted and the same amongst the disparate systems.
Introducing Conflict-free Replicated Data Type (CRDT).
Building a Resilient Data Platform with Write-Ahead Log at Netflix
Rethinking Netflix’s Edge Load Balancing
Additional reading
Load is not what you should balance: Introducing Prequal
Implementing the Dots “Intent Engine”
This is where modelling is very important and creating frameworks that are vendor agnostic and data driven.
What I mean by this is, historically vendors have created their own way of laying out and storing the data which drives their network element(s), however when you have several vendors in your ecosystem, keeping data models mapped per vendor becomes unsustainable, especially when the vendor changes their models between NOS versions.
So as explored above, keeping your own data model which can be abstracted per vendor is how you can drive your intended outcomes (more on “Implementation Engine” shortly).
What the F*&k is an Intent!?
Intents in my world are finite actions, i.e., “I would like to eat a tasty bowl of rice”, in the realms of reality, for that term either; the bowl will become empty or my stomach will become full.
In networking a finite request of a network element to perform a task would be:
provision network element X with serial number Y for role Z with profile 1234.
add feature X to network element Y from updated profile 4567.
provision customer X for product Y over path Z starting a date A time B and finishing at date C time D.
🎶 Woop-woop, that's the sound of da police 🎶 “Policy Engine”
Policies are what you would expect, the ‘policing’ of the Intents. They should be set by the business/ organisation objectives and follow an interpretation of Asimov’s Three Laws of Robotics:
A Network Ecosystem may not injure the network or, through inaction, allow the network to come to harm.
A Network Ecosystem must obey the orders given it by human beings, except where such orders would conflict with the First Law.
A Network Ecosystem must protect its own existence as long as such protection does not conflict with the First or Second Law.
So if an Intent is finite, then you’ve guessed it, a Policy is infinite. Using the boundaries set by the business/ organisation logic and the telemetry from the Ingest Engine to measure the KPIs/ metrics/ data coming from the network elements, it is the binding ‘force’ behind keeping a Network Ecosystem stable and running as per the require Intent(s) of the Network Operator.
That Cute, However What Are My Options? “Implementation Engine”
If creating your own data structures, and relationships is not something you want to do, there are quite a few tools out there now. One I would recommend exploring is NetBox (no I don’t work for them, and no this isn’t a paid endorsement).
NetBox has build the relationship between networking elements, circuits, IP address, rack layouts … etc., all for you in one hand tool. They have also extended it’s abilities with APIs and the community have created various plugins, MCPs … etc., which with a Policy Engine (I’ll come onto that next), will start stitching a lot of this together for you, example https://community.juniper.net/blogs/victor-ganjian/2025/11/01/network-automation-with-ai-and-junos-mcp-server.
Summary
Balancing the requirements of a business/ organisation, against the demands (or the perceived ones) of the customer/ end-user has always been a constant struggle, as the business/ organisation wants to be at the top of the listings for its market (shareholders/ return on investment), and the customer/ end-user wants to pay the least amount for the best service possible.

So leveraging data to drive towards an autonomous future, helps (within reason) improve good with constant feedback, if scaled correctly reduce cost by not wasting time/ duplication of effort/ systems … etc., and finally improve speed for the mundane routines1.
Overall, none of this is easy, however most of this is automating mundane tasks, speeding up data analysis.
Notice that the above is about process efficiency and not human, as the perceived view I’ve seen over the last 20+ years from business leaders is “… the X is slow/ expense because of the ‘human factor’ …”. What they don’t realise is that the process(es) put in place (usually to stop excess spend, reputation damage … etc.), can (if not regularly reviewed) cause slow downs and curtail individuals from using their high order functions to produce better outcomes.
That’s not to say that policy and process don’t have their place, heck they’re the fundamental building blocks of what I’ve outlined above, just make sure next time the “human factor” comes up in “causing business/ production slow down/ poor turnover/ results”, you also review the policies and processes to see if there’s improvements there first.